SIMD (Vector Processing)#
Numerical software means a lot of computation for solutions. The computation calls for a huge amount of cycles in the computer (processor). Users always want shorter processing time. The demand for faster speed keeps increasing at a faster pace than the advancement of the computer technologies.
There are typically two ways to speed up:
Use fewer computation: Code optimization.
Do more computation concurrently: Parallelism.
Parallelism appears in various levels, from high to low:
- Cluster or server farm
Multiple computers are networked together to solve one problem.
- Multiple core with multiple threads
Multiple threads runs concurrently on the multiple cores on a single computer host.
- Single instruction multiple data (SIMD)
Computers offer special instructions that can process multiple data at one time to achieve data parallelism.
Note
There is also instruction-level parallelism (ILP) that enables execution of multiple instructions in parallel on a single processor core. It involves the use of superscalar, pipelining, out-of-order execution, branch prediction, etc.
When speed is in need, we do everything to run faster, but it is wise to begin with low-hanging fruit. Instruction-level parallelism is generally easier than that in the higher level, because programmers should only take care of the details required by the architecture.
In this chapter, we will discuss the fundamental knowledge for bringing SIMD (which is also called vector processing) into a software system.
Types of Parallel Software Development#
The popular computer architecture is based on sequential processing. The most fundamental processing unit executes instructions one by one.
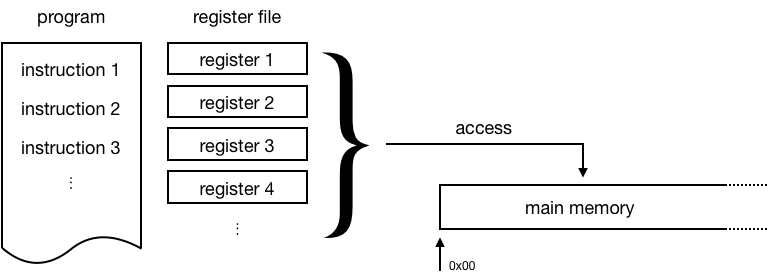
Assuming the processor can only perform sequential processing, we need multiple processors to perform parallel processing. Differentiated by the memory access, the parallelism can be broadly set to two categories:
Shared-memory parallel processing
Distributed-memory parallel processing
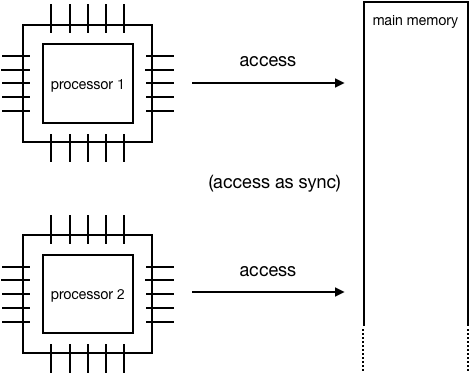
Shared-Memory Parallel Processing#
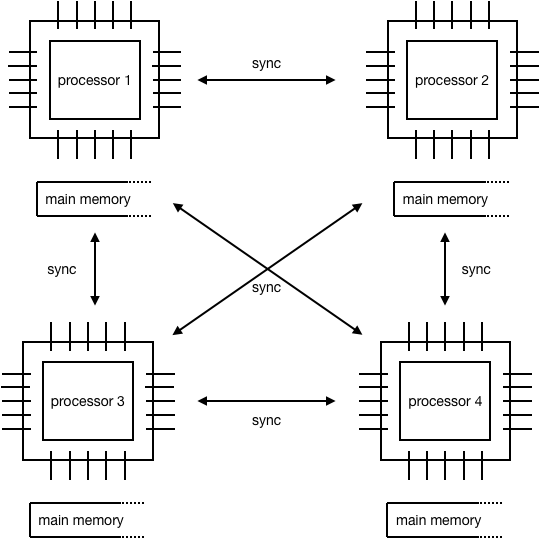
Distributed-Memory Parallel Processing#
Vector Processing#
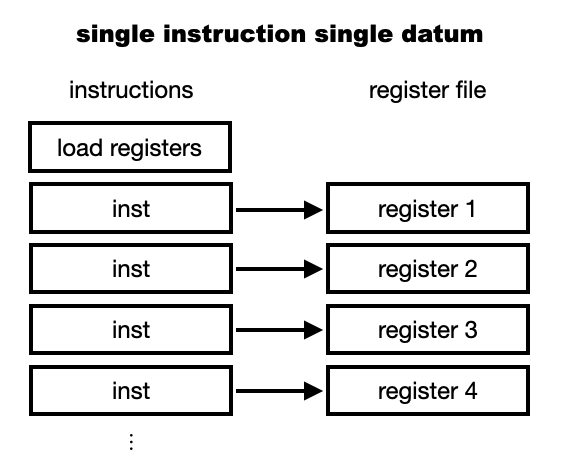
When the parallelism happens in the processor (one processing unit or core), it is done once for a single instruction with multiple data (SIMD). It is called vector processing.
Before showing what is vector processing, let us see the ordinary scalar execution:
The vector execution uses a wider register so that it can perform an operation for multiple data at once:
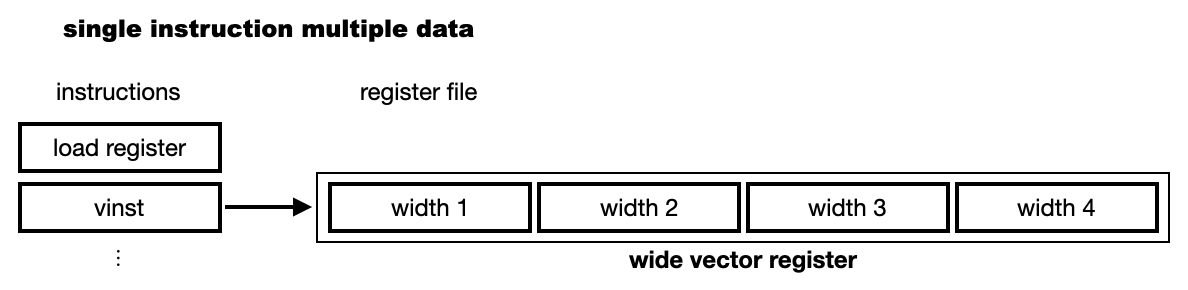
SIMD Instructions#
CPU Capabilities#
To take advantage of SIMD, we will need to inspect the CPU instructions, or the assembly. But most of the time we stay in high-level languages. The way we deal with the assembly is to get familiar with the instructions, e.g., using x86 and amd64 instruction reference.
x86 provides a series of SIMD instructions, including
64-bit: MMX
128-bit: SSE, SSE2, SSE3, SSE4, SSE4.1, SSE4.2 (streaming SIMD extension)
256-bit: AVX, AVX2 (advanced vector extension)
512-bit: AVX-512
Recent processors usually are equipped with AVX2, which was released with Haswell in 2013. Before asking the compiler to use the specific instruction set, query the operating system for the CPU capabilities.
print("Check on", platform.system())
if 'Linux' == platform.system():
# check whether your cpu supports avx2 on linux
!grep flags /proc/cpuinfo
elif 'Darwin' == platform.system():
# check whether your cpu supports avx2 on mac
!sysctl -a | grep machdep.cpu.*features
X86 Intrinsic Functions#
Major compilers provide header files for using the intrinsic functions that can be directly translated into the SIMD instructions:
<mmintrin.h>: MMX<xmmintrin.h>: SSE<emmintrin.h>: SSE2<pmmintrin.h>: SSE3<tmmintrin.h>: SSSE3<smmintrin.h>: SSE4.1<nmmintrin.h>: SSE4.2<ammintrin.h>: SSE4A<immintrin.h>: AVX<zmmintrin.h>: AVX512
You may also use <x86intrin.h> which includes everything.
With the intrinsic functions, programmers don’t need to really write assembly, and can stay in the high-level languages most of the time. The intrinsic functions correspond to x86 instructions. An example of using it:
__m256 * ma = (__m256 *) (&a[i*width]);
__m256 * mb = (__m256 *) (&b[i*width]);
__m256 * mr = (__m256 *) (&r[i*width]);
*mr = _mm256_mul_ps(*ma, *mb);
Intel intrinsic guide: Intel maintains a website to show the available intrinsics: https://software.intel.com/sites/landingpage/IntrinsicsGuide/ . Consult and remember it when needed.
Using intrinsics and SIMD for optimization is a tedious process. The materials presented here are not a complete guide to you, but show you one way to study and measure the benefits. The measurement is important to assess whether or not you need the optimization.
We will use an example to show how to use the 256-bit-wide AVX to perform vector multiplication for 8 single-precision floating-point values:
constexpr const size_t width = 8;
constexpr const size_t repeat = 1024 * 1024;
constexpr const size_t nelem = width * repeat;
The data arrays are:
float * arr = (float *) aligned_alloc(32, nelem * sizeof(float));
float * brr = (float *) aligned_alloc(32, nelem * sizeof(float));
float * rrr1 = (float *) aligned_alloc(32, nelem * sizeof(float));
float * rrr2 = (float *) aligned_alloc(32, nelem * sizeof(float));
width: 8
nelem: 8388608
arr: 0x7fbf40800000
brr: 0x7fbf42800000
rrr1: 0x7fbf44800000
rrr2: 0x7fbf46800000
The full example code can be found in mul.cpp.
Symbol Table#
We will use radare2 to inspect the assembly of the generated image. As the first step, before really checking the assembly, we need to identify what functions to be inspected from the symbol table.
$ r2 -Aqc "e scr.color=0 ; afl" mul
... some irrelevant prints ...
0x100001720 3 178 sym.multiply1_loop_float__float__float_
0x1000017e0 3 102 sym.multiply1_simd_float__float__float_
0x100001850 3 354 sym.multiply3_loop_float__float__float_
0x1000019c0 3 107 sym.multiply3_simd_float__float__float_
0x100001a30 3 546 sym.multiply5_loop_float__float__float_
0x100001c60 3 87 sym.multiply5_simd_float__float__float_
... symbols that do not matter ...
...
0x1000038c0 1 6 sym.imp.std::__1::ios_base::getloc___const
...
1 Multiplication#
To demonstrate the effect of different ratio of calculations to memory access, I use 3 sets of multiplication. The first set uses 1 multiplication. We compare the two versions of the code to see that SIMD does not help much with so little calculations: (i) loop and (ii) SIMD.
void multiply1_loop(float* a, float* b, float* r)
{
for (size_t i=0; i<repeat*width; i+=width)
{
for (size_t j=i; j<i+width; ++j)
{
r[j] = a[j] * b[j];
}
}
}
void multiply1_simd(float* a, float* b, float* r)
{
for (size_t i=0; i<repeat; ++i)
{
__m256 * ma = (__m256 *) (&a[i*width]);
__m256 * mb = (__m256 *) (&b[i*width]);
__m256 * mr = (__m256 *) (&r[i*width]);
*mr = _mm256_mul_ps(*ma, *mb);
}
}
The corresponding assembly code is:
$ r2 -Aqc "e scr.color=0 ; sf sym.multiply1_loop_float__float__float_ ; pdf" mul
...
│ ; CODE XREF from multiply1_loop(float*, float*, float*) @ 0x1000017ca
│ ┌─> 0x100001730 c5fa10448720 vmovss xmm0, dword [rdi + rax*4 + 0x20]
│ ╎ 0x100001736 c5fa59448620 vmulss xmm0, xmm0, dword [rsi + rax*4 + 0x20]
│ ╎ 0x10000173c c5fa11448220 vmovss dword [rdx + rax*4 + 0x20], xmm0
│ ╎ 0x100001742 c5fa10448724 vmovss xmm0, dword [rdi + rax*4 + 0x24]
│ ╎ 0x100001748 c5fa59448624 vmulss xmm0, xmm0, dword [rsi + rax*4 + 0x24]
│ ╎ 0x10000174e c5fa11448224 vmovss dword [rdx + rax*4 + 0x24], xmm0
│ ╎ 0x100001754 c5fa10448728 vmovss xmm0, dword [rdi + rax*4 + 0x28]
│ ╎ 0x10000175a c5fa59448628 vmulss xmm0, xmm0, dword [rsi + rax*4 + 0x28]
│ ╎ 0x100001760 c5fa11448228 vmovss dword [rdx + rax*4 + 0x28], xmm0
│ ╎ 0x100001766 c5fa1044872c vmovss xmm0, dword [rdi + rax*4 + 0x2c]
│ ╎ 0x10000176c c5fa5944862c vmulss xmm0, xmm0, dword [rsi + rax*4 + 0x2c]
│ ╎ 0x100001772 c5fa1144822c vmovss dword [rdx + rax*4 + 0x2c], xmm0
│ ╎ 0x100001778 c5fa10448730 vmovss xmm0, dword [rdi + rax*4 + 0x30]
│ ╎ 0x10000177e c5fa59448630 vmulss xmm0, xmm0, dword [rsi + rax*4 + 0x30]
│ ╎ 0x100001784 c5fa11448230 vmovss dword [rdx + rax*4 + 0x30], xmm0
│ ╎ 0x10000178a c5fa10448734 vmovss xmm0, dword [rdi + rax*4 + 0x34]
│ ╎ 0x100001790 c5fa59448634 vmulss xmm0, xmm0, dword [rsi + rax*4 + 0x34]
│ ╎ 0x100001796 c5fa11448234 vmovss dword [rdx + rax*4 + 0x34], xmm0
│ ╎ 0x10000179c c5fa10448738 vmovss xmm0, dword [rdi + rax*4 + 0x38]
│ ╎ 0x1000017a2 c5fa59448638 vmulss xmm0, xmm0, dword [rsi + rax*4 + 0x38]
│ ╎ 0x1000017a8 c5fa11448238 vmovss dword [rdx + rax*4 + 0x38], xmm0
│ ╎ 0x1000017ae c5fa1044873c vmovss xmm0, dword [rdi + rax*4 + 0x3c]
│ ╎ 0x1000017b4 c5fa5944863c vmulss xmm0, xmm0, dword [rsi + rax*4 + 0x3c]
│ ╎ 0x1000017ba c5fa1144823c vmovss dword [rdx + rax*4 + 0x3c], xmm0
│ ╎ 0x1000017c0 4883c008 add rax, 8
│ ╎ 0x1000017c4 483df8ff7f00 cmp rax, 0x7ffff8
│ └─< 0x1000017ca 0f8260ffffff jb 0x100001730
...
$ r2 -Aqc "e scr.color=0 ; sf sym.multiply1_simd_float__float__float_ ; pdf" mul
...
│ ; CODE XREF from multiply1_simd(float*, float*, float*) @ 0x10000183f
│ ┌─> 0x1000017f0 c5fc280407 vmovaps ymm0, ymmword [rdi + rax]
│ ╎ 0x1000017f5 c5fc590406 vmulps ymm0, ymm0, ymmword [rsi + rax]
│ ╎ 0x1000017fa c5fc290402 vmovaps ymmword [rdx + rax], ymm0
│ ╎ 0x1000017ff c5fc28440720 vmovaps ymm0, ymmword [rdi + rax + 0x20]
│ ╎ 0x100001805 c5fc59440620 vmulps ymm0, ymm0, ymmword [rsi + rax + 0x20]
│ ╎ 0x10000180b c5fc29440220 vmovaps ymmword [rdx + rax + 0x20], ymm0
│ ╎ 0x100001811 c5fc28440740 vmovaps ymm0, ymmword [rdi + rax + 0x40]
│ ╎ 0x100001817 c5fc59440640 vmulps ymm0, ymm0, ymmword [rsi + rax + 0x40]
│ ╎ 0x10000181d c5fc29440240 vmovaps ymmword [rdx + rax + 0x40], ymm0
│ ╎ 0x100001823 c5fc28440760 vmovaps ymm0, ymmword [rdi + rax + 0x60]
│ ╎ 0x100001829 c5fc59440660 vmulps ymm0, ymm0, ymmword [rsi + rax + 0x60]
│ ╎ 0x10000182f c5fc29440260 vmovaps ymmword [rdx + rax + 0x60], ymm0
│ ╎ 0x100001835 4883e880 sub rax, 0xffffffffffffff80
│ ╎ 0x100001839 483d00000002 cmp rax, 0x2000000
│ └─< 0x10000183f 75af jne 0x1000017f0
...
In the runtime benchmark, the SIMD/AVX version is faster, but with a small margin. The SIMD version is only 1.48 times faster than the loop version:
1 multiplication by loop takes: 0.00502769 sec
1 multiplication by simd takes: 0.00339758 sec
3 Multiplication#
The second set uses 3 multiplications. The source code for the loop and SIMD versions are:
void multiply3_loop(float* a, float* b, float* r)
{
for (size_t i=0; i<repeat*width; i+=width)
{
for (size_t j=i; j<i+width; ++j)
{
r[j] = a[j] * a[j];
r[j] *= b[j];
r[j] *= b[j];
}
}
}
void multiply3_simd(float* a, float* b, float* r)
{
for (size_t i=0; i<repeat; ++i)
{
__m256 * ma = (__m256 *) (&a[i*width]);
__m256 * mb = (__m256 *) (&b[i*width]);
__m256 * mr = (__m256 *) (&r[i*width]);
*mr = _mm256_mul_ps(*ma, *ma);
*mr = _mm256_mul_ps(*mr, *mb);
*mr = _mm256_mul_ps(*mr, *mb);
}
}
The corresponding assembly code is:
$ r2 -Aqc "e scr.color=0 ; sf sym.multiply3_loop_float__float__float_ ; pdf" mul
...
│ ; CODE XREF from multiply3_loop(float*, float*, float*) @ 0x1000019aa
│ ┌─> 0x100001860 c5fa10448720 vmovss xmm0, dword [rdi + rax*4 + 0x20]
│ ╎ 0x100001866 c5fa59c0 vmulss xmm0, xmm0, xmm0
│ ╎ 0x10000186a c5fa11448220 vmovss dword [rdx + rax*4 + 0x20], xmm0
│ ╎ 0x100001870 c5fa59448620 vmulss xmm0, xmm0, dword [rsi + rax*4 + 0x20]
│ ╎ 0x100001876 c5fa11448220 vmovss dword [rdx + rax*4 + 0x20], xmm0
│ ╎ 0x10000187c c5fa59448620 vmulss xmm0, xmm0, dword [rsi + rax*4 + 0x20]
│ ╎ 0x100001882 c5fa11448220 vmovss dword [rdx + rax*4 + 0x20], xmm0
│ ╎ 0x100001888 c5fa10448724 vmovss xmm0, dword [rdi + rax*4 + 0x24]
│ ╎ 0x10000188e c5fa59c0 vmulss xmm0, xmm0, xmm0
│ ╎ 0x100001892 c5fa11448224 vmovss dword [rdx + rax*4 + 0x24], xmm0
│ ╎ 0x100001898 c5fa59448624 vmulss xmm0, xmm0, dword [rsi + rax*4 + 0x24]
│ ╎ 0x10000189e c5fa11448224 vmovss dword [rdx + rax*4 + 0x24], xmm0
│ ╎ 0x1000018a4 c5fa59448624 vmulss xmm0, xmm0, dword [rsi + rax*4 + 0x24]
│ ╎ 0x1000018aa c5fa11448224 vmovss dword [rdx + rax*4 + 0x24], xmm0
│ ╎ 0x1000018b0 c5fa10448728 vmovss xmm0, dword [rdi + rax*4 + 0x28]
│ ╎ 0x1000018b6 c5fa59c0 vmulss xmm0, xmm0, xmm0
│ ╎ 0x1000018ba c5fa11448228 vmovss dword [rdx + rax*4 + 0x28], xmm0
│ ╎ 0x1000018c0 c5fa59448628 vmulss xmm0, xmm0, dword [rsi + rax*4 + 0x28]
│ ╎ 0x1000018c6 c5fa11448228 vmovss dword [rdx + rax*4 + 0x28], xmm0
│ ╎ 0x1000018cc c5fa59448628 vmulss xmm0, xmm0, dword [rsi + rax*4 + 0x28]
│ ╎ 0x1000018d2 c5fa11448228 vmovss dword [rdx + rax*4 + 0x28], xmm0
│ ╎ 0x1000018d8 c5fa1044872c vmovss xmm0, dword [rdi + rax*4 + 0x2c]
│ ╎ 0x1000018de c5fa59c0 vmulss xmm0, xmm0, xmm0
│ ╎ 0x1000018e2 c5fa1144822c vmovss dword [rdx + rax*4 + 0x2c], xmm0
│ ╎ 0x1000018e8 c5fa5944862c vmulss xmm0, xmm0, dword [rsi + rax*4 + 0x2c]
│ ╎ 0x1000018ee c5fa1144822c vmovss dword [rdx + rax*4 + 0x2c], xmm0
│ ╎ 0x1000018f4 c5fa5944862c vmulss xmm0, xmm0, dword [rsi + rax*4 + 0x2c]
│ ╎ 0x1000018fa c5fa1144822c vmovss dword [rdx + rax*4 + 0x2c], xmm0
│ ╎ 0x100001900 c5fa10448730 vmovss xmm0, dword [rdi + rax*4 + 0x30]
│ ╎ 0x100001906 c5fa59c0 vmulss xmm0, xmm0, xmm0
│ ╎ 0x10000190a c5fa11448230 vmovss dword [rdx + rax*4 + 0x30], xmm0
│ ╎ 0x100001910 c5fa59448630 vmulss xmm0, xmm0, dword [rsi + rax*4 + 0x30]
│ ╎ 0x100001916 c5fa11448230 vmovss dword [rdx + rax*4 + 0x30], xmm0
│ ╎ 0x10000191c c5fa59448630 vmulss xmm0, xmm0, dword [rsi + rax*4 + 0x30]
│ ╎ 0x100001922 c5fa11448230 vmovss dword [rdx + rax*4 + 0x30], xmm0
│ ╎ 0x100001928 c5fa10448734 vmovss xmm0, dword [rdi + rax*4 + 0x34]
│ ╎ 0x10000192e c5fa59c0 vmulss xmm0, xmm0, xmm0
│ ╎ 0x100001932 c5fa11448234 vmovss dword [rdx + rax*4 + 0x34], xmm0
│ ╎ 0x100001938 c5fa59448634 vmulss xmm0, xmm0, dword [rsi + rax*4 + 0x34]
│ ╎ 0x10000193e c5fa11448234 vmovss dword [rdx + rax*4 + 0x34], xmm0
│ ╎ 0x100001944 c5fa59448634 vmulss xmm0, xmm0, dword [rsi + rax*4 + 0x34]
│ ╎ 0x10000194a c5fa11448234 vmovss dword [rdx + rax*4 + 0x34], xmm0
│ ╎ 0x100001950 c5fa10448738 vmovss xmm0, dword [rdi + rax*4 + 0x38]
│ ╎ 0x100001956 c5fa59c0 vmulss xmm0, xmm0, xmm0
│ ╎ 0x10000195a c5fa11448238 vmovss dword [rdx + rax*4 + 0x38], xmm0
│ ╎ 0x100001960 c5fa59448638 vmulss xmm0, xmm0, dword [rsi + rax*4 + 0x38]
│ ╎ 0x100001966 c5fa11448238 vmovss dword [rdx + rax*4 + 0x38], xmm0
│ ╎ 0x10000196c c5fa59448638 vmulss xmm0, xmm0, dword [rsi + rax*4 + 0x38]
│ ╎ 0x100001972 c5fa11448238 vmovss dword [rdx + rax*4 + 0x38], xmm0
│ ╎ 0x100001978 c5fa1044873c vmovss xmm0, dword [rdi + rax*4 + 0x3c]
│ ╎ 0x10000197e c5fa59c0 vmulss xmm0, xmm0, xmm0
│ ╎ 0x100001982 c5fa1144823c vmovss dword [rdx + rax*4 + 0x3c], xmm0
│ ╎ 0x100001988 c5fa5944863c vmulss xmm0, xmm0, dword [rsi + rax*4 + 0x3c]
│ ╎ 0x10000198e c5fa1144823c vmovss dword [rdx + rax*4 + 0x3c], xmm0
│ ╎ 0x100001994 c5fa5944863c vmulss xmm0, xmm0, dword [rsi + rax*4 + 0x3c]
│ ╎ 0x10000199a c5fa1144823c vmovss dword [rdx + rax*4 + 0x3c], xmm0
│ ╎ 0x1000019a0 4883c008 add rax, 8
│ ╎ 0x1000019a4 483df8ff7f00 cmp rax, 0x7ffff8
│ └─< 0x1000019aa 0f82b0feffff jb 0x100001860
...
$ r2 -Aqc "e scr.color=0 ; sf sym.multiply3_simd_float__float__float_ ; pdf" mul
...
│ ; CODE XREF from multiply3_simd(float*, float*, float*) @ 0x100001a24
│ ┌─> 0x1000019d0 c5fc280407 vmovaps ymm0, ymmword [rdi + rax]
│ ╎ 0x1000019d5 c5fc59c0 vmulps ymm0, ymm0, ymm0
│ ╎ 0x1000019d9 c5fc290402 vmovaps ymmword [rdx + rax], ymm0
│ ╎ 0x1000019de c5fc590406 vmulps ymm0, ymm0, ymmword [rsi + rax]
│ ╎ 0x1000019e3 c5fc290402 vmovaps ymmword [rdx + rax], ymm0
│ ╎ 0x1000019e8 c5fc590406 vmulps ymm0, ymm0, ymmword [rsi + rax]
│ ╎ 0x1000019ed c5fc290402 vmovaps ymmword [rdx + rax], ymm0
│ ╎ 0x1000019f2 c5fc28440720 vmovaps ymm0, ymmword [rdi + rax + 0x20]
│ ╎ 0x1000019f8 c5fc59c0 vmulps ymm0, ymm0, ymm0
│ ╎ 0x1000019fc c5fc29440220 vmovaps ymmword [rdx + rax + 0x20], ymm0
│ ╎ 0x100001a02 c5fc59440620 vmulps ymm0, ymm0, ymmword [rsi + rax + 0x20]
│ ╎ 0x100001a08 c5fc29440220 vmovaps ymmword [rdx + rax + 0x20], ymm0
│ ╎ 0x100001a0e c5fc59440620 vmulps ymm0, ymm0, ymmword [rsi + rax + 0x20]
│ ╎ 0x100001a14 c5fc29440220 vmovaps ymmword [rdx + rax + 0x20], ymm0
│ ╎ 0x100001a1a 4883c040 add rax, 0x40 ; 64
│ ╎ 0x100001a1e 483d00000002 cmp rax, 0x2000000
│ └─< 0x100001a24 75aa jne 0x1000019d0
...
The speed-up of the SIMD version to the loop version significantly increases to 3.24 times:
3 multiplication by loop takes: 0.0111576 sec
3 multiplication by simd takes: 0.00344309 sec
5 Multiplication#
The third (last) set uses 5 multiplications. The source code for the loop and SIMD versions are:
void multiply5_loop(float* a, float* b, float* r)
{
for (size_t i=0; i<repeat*width; i+=width)
{
for (size_t j=i; j<i+width; ++j)
{
r[j] = a[j] * a[j];
r[j] *= a[j];
r[j] *= b[j];
r[j] *= b[j];
r[j] *= b[j];
}
}
}
void multiply5_simd(float* a, float* b, float* r)
{
for (size_t i=0; i<repeat; ++i)
{
__m256 * ma = (__m256 *) (&a[i*width]);
__m256 * mb = (__m256 *) (&b[i*width]);
__m256 * mr = (__m256 *) (&r[i*width]);
*mr = _mm256_mul_ps(*ma, *ma);
*mr = _mm256_mul_ps(*mr, *ma);
*mr = _mm256_mul_ps(*mr, *mb);
*mr = _mm256_mul_ps(*mr, *mb);
*mr = _mm256_mul_ps(*mr, *mb);
}
}
The corresponding assembly code is:
$ r2 -Aqc "e scr.color=0 ; sf sym.multiply5_loop_float__float__float_ ; pdf" mul
...
│ ; CODE XREF from multiply5_loop(float*, float*, float*) @ 0x100001c4a
│ ┌─> 0x100001a40 c5fa10448720 vmovss xmm0, dword [rdi + rax*4 + 0x20]
│ ╎ 0x100001a46 c5fa59c0 vmulss xmm0, xmm0, xmm0
│ ╎ 0x100001a4a c5fa11448220 vmovss dword [rdx + rax*4 + 0x20], xmm0
│ ╎ 0x100001a50 c5fa59448720 vmulss xmm0, xmm0, dword [rdi + rax*4 + 0x20]
│ ╎ 0x100001a56 c5fa11448220 vmovss dword [rdx + rax*4 + 0x20], xmm0
│ ╎ 0x100001a5c c5fa59448620 vmulss xmm0, xmm0, dword [rsi + rax*4 + 0x20]
│ ╎ 0x100001a62 c5fa11448220 vmovss dword [rdx + rax*4 + 0x20], xmm0
│ ╎ 0x100001a68 c5fa59448620 vmulss xmm0, xmm0, dword [rsi + rax*4 + 0x20]
│ ╎ 0x100001a6e c5fa11448220 vmovss dword [rdx + rax*4 + 0x20], xmm0
│ ╎ 0x100001a74 c5fa59448620 vmulss xmm0, xmm0, dword [rsi + rax*4 + 0x20]
│ ╎ 0x100001a7a c5fa11448220 vmovss dword [rdx + rax*4 + 0x20], xmm0
│ ╎ 0x100001a80 c5fa10448724 vmovss xmm0, dword [rdi + rax*4 + 0x24]
│ ╎ 0x100001a86 c5fa59c0 vmulss xmm0, xmm0, xmm0
│ ╎ 0x100001a8a c5fa11448224 vmovss dword [rdx + rax*4 + 0x24], xmm0
│ ╎ 0x100001a90 c5fa59448724 vmulss xmm0, xmm0, dword [rdi + rax*4 + 0x24]
│ ╎ 0x100001a96 c5fa11448224 vmovss dword [rdx + rax*4 + 0x24], xmm0
│ ╎ 0x100001a9c c5fa59448624 vmulss xmm0, xmm0, dword [rsi + rax*4 + 0x24]
│ ╎ 0x100001aa2 c5fa11448224 vmovss dword [rdx + rax*4 + 0x24], xmm0
│ ╎ 0x100001aa8 c5fa59448624 vmulss xmm0, xmm0, dword [rsi + rax*4 + 0x24]
│ ╎ 0x100001aae c5fa11448224 vmovss dword [rdx + rax*4 + 0x24], xmm0
│ ╎ 0x100001ab4 c5fa59448624 vmulss xmm0, xmm0, dword [rsi + rax*4 + 0x24]
│ ╎ 0x100001aba c5fa11448224 vmovss dword [rdx + rax*4 + 0x24], xmm0
│ ╎ 0x100001ac0 c5fa10448728 vmovss xmm0, dword [rdi + rax*4 + 0x28]
│ ╎ 0x100001ac6 c5fa59c0 vmulss xmm0, xmm0, xmm0
│ ╎ 0x100001aca c5fa11448228 vmovss dword [rdx + rax*4 + 0x28], xmm0
│ ╎ 0x100001ad0 c5fa59448728 vmulss xmm0, xmm0, dword [rdi + rax*4 + 0x28]
│ ╎ 0x100001ad6 c5fa11448228 vmovss dword [rdx + rax*4 + 0x28], xmm0
│ ╎ 0x100001adc c5fa59448628 vmulss xmm0, xmm0, dword [rsi + rax*4 + 0x28]
│ ╎ 0x100001ae2 c5fa11448228 vmovss dword [rdx + rax*4 + 0x28], xmm0
│ ╎ 0x100001ae8 c5fa59448628 vmulss xmm0, xmm0, dword [rsi + rax*4 + 0x28]
│ ╎ 0x100001aee c5fa11448228 vmovss dword [rdx + rax*4 + 0x28], xmm0
│ ╎ 0x100001af4 c5fa59448628 vmulss xmm0, xmm0, dword [rsi + rax*4 + 0x28]
│ ╎ 0x100001afa c5fa11448228 vmovss dword [rdx + rax*4 + 0x28], xmm0
│ ╎ 0x100001b00 c5fa1044872c vmovss xmm0, dword [rdi + rax*4 + 0x2c]
│ ╎ 0x100001b06 c5fa59c0 vmulss xmm0, xmm0, xmm0
│ ╎ 0x100001b0a c5fa1144822c vmovss dword [rdx + rax*4 + 0x2c], xmm0
│ ╎ 0x100001b10 c5fa5944872c vmulss xmm0, xmm0, dword [rdi + rax*4 + 0x2c]
│ ╎ 0x100001b16 c5fa1144822c vmovss dword [rdx + rax*4 + 0x2c], xmm0
│ ╎ 0x100001b1c c5fa5944862c vmulss xmm0, xmm0, dword [rsi + rax*4 + 0x2c]
│ ╎ 0x100001b22 c5fa1144822c vmovss dword [rdx + rax*4 + 0x2c], xmm0
│ ╎ 0x100001b28 c5fa5944862c vmulss xmm0, xmm0, dword [rsi + rax*4 + 0x2c]
│ ╎ 0x100001b2e c5fa1144822c vmovss dword [rdx + rax*4 + 0x2c], xmm0
│ ╎ 0x100001b34 c5fa5944862c vmulss xmm0, xmm0, dword [rsi + rax*4 + 0x2c]
│ ╎ 0x100001b3a c5fa1144822c vmovss dword [rdx + rax*4 + 0x2c], xmm0
│ ╎ 0x100001b40 c5fa10448730 vmovss xmm0, dword [rdi + rax*4 + 0x30]
│ ╎ 0x100001b46 c5fa59c0 vmulss xmm0, xmm0, xmm0
│ ╎ 0x100001b4a c5fa11448230 vmovss dword [rdx + rax*4 + 0x30], xmm0
│ ╎ 0x100001b50 c5fa59448730 vmulss xmm0, xmm0, dword [rdi + rax*4 + 0x30]
│ ╎ 0x100001b56 c5fa11448230 vmovss dword [rdx + rax*4 + 0x30], xmm0
│ ╎ 0x100001b5c c5fa59448630 vmulss xmm0, xmm0, dword [rsi + rax*4 + 0x30]
│ ╎ 0x100001b62 c5fa11448230 vmovss dword [rdx + rax*4 + 0x30], xmm0
│ ╎ 0x100001b68 c5fa59448630 vmulss xmm0, xmm0, dword [rsi + rax*4 + 0x30]
│ ╎ 0x100001b6e c5fa11448230 vmovss dword [rdx + rax*4 + 0x30], xmm0
│ ╎ 0x100001b74 c5fa59448630 vmulss xmm0, xmm0, dword [rsi + rax*4 + 0x30]
│ ╎ 0x100001b7a c5fa11448230 vmovss dword [rdx + rax*4 + 0x30], xmm0
│ ╎ 0x100001b80 c5fa10448734 vmovss xmm0, dword [rdi + rax*4 + 0x34]
│ ╎ 0x100001b86 c5fa59c0 vmulss xmm0, xmm0, xmm0
│ ╎ 0x100001b8a c5fa11448234 vmovss dword [rdx + rax*4 + 0x34], xmm0
│ ╎ 0x100001b90 c5fa59448734 vmulss xmm0, xmm0, dword [rdi + rax*4 + 0x34]
│ ╎ 0x100001b96 c5fa11448234 vmovss dword [rdx + rax*4 + 0x34], xmm0
│ ╎ 0x100001b9c c5fa59448634 vmulss xmm0, xmm0, dword [rsi + rax*4 + 0x34]
│ ╎ 0x100001ba2 c5fa11448234 vmovss dword [rdx + rax*4 + 0x34], xmm0
│ ╎ 0x100001ba8 c5fa59448634 vmulss xmm0, xmm0, dword [rsi + rax*4 + 0x34]
│ ╎ 0x100001bae c5fa11448234 vmovss dword [rdx + rax*4 + 0x34], xmm0
│ ╎ 0x100001bb4 c5fa59448634 vmulss xmm0, xmm0, dword [rsi + rax*4 + 0x34]
│ ╎ 0x100001bba c5fa11448234 vmovss dword [rdx + rax*4 + 0x34], xmm0
│ ╎ 0x100001bc0 c5fa10448738 vmovss xmm0, dword [rdi + rax*4 + 0x38]
│ ╎ 0x100001bc6 c5fa59c0 vmulss xmm0, xmm0, xmm0
│ ╎ 0x100001bca c5fa11448238 vmovss dword [rdx + rax*4 + 0x38], xmm0
│ ╎ 0x100001bd0 c5fa59448738 vmulss xmm0, xmm0, dword [rdi + rax*4 + 0x38]
│ ╎ 0x100001bd6 c5fa11448238 vmovss dword [rdx + rax*4 + 0x38], xmm0
│ ╎ 0x100001bdc c5fa59448638 vmulss xmm0, xmm0, dword [rsi + rax*4 + 0x38]
│ ╎ 0x100001be2 c5fa11448238 vmovss dword [rdx + rax*4 + 0x38], xmm0
│ ╎ 0x100001be8 c5fa59448638 vmulss xmm0, xmm0, dword [rsi + rax*4 + 0x38]
│ ╎ 0x100001bee c5fa11448238 vmovss dword [rdx + rax*4 + 0x38], xmm0
│ ╎ 0x100001bf4 c5fa59448638 vmulss xmm0, xmm0, dword [rsi + rax*4 + 0x38]
│ ╎ 0x100001bfa c5fa11448238 vmovss dword [rdx + rax*4 + 0x38], xmm0
│ ╎ 0x100001c00 c5fa1044873c vmovss xmm0, dword [rdi + rax*4 + 0x3c]
│ ╎ 0x100001c06 c5fa59c0 vmulss xmm0, xmm0, xmm0
│ ╎ 0x100001c0a c5fa1144823c vmovss dword [rdx + rax*4 + 0x3c], xmm0
│ ╎ 0x100001c10 c5fa5944873c vmulss xmm0, xmm0, dword [rdi + rax*4 + 0x3c]
│ ╎ 0x100001c16 c5fa1144823c vmovss dword [rdx + rax*4 + 0x3c], xmm0
│ ╎ 0x100001c1c c5fa5944863c vmulss xmm0, xmm0, dword [rsi + rax*4 + 0x3c]
│ ╎ 0x100001c22 c5fa1144823c vmovss dword [rdx + rax*4 + 0x3c], xmm0
│ ╎ 0x100001c28 c5fa5944863c vmulss xmm0, xmm0, dword [rsi + rax*4 + 0x3c]
│ ╎ 0x100001c2e c5fa1144823c vmovss dword [rdx + rax*4 + 0x3c], xmm0
│ ╎ 0x100001c34 c5fa5944863c vmulss xmm0, xmm0, dword [rsi + rax*4 + 0x3c]
│ ╎ 0x100001c3a c5fa1144823c vmovss dword [rdx + rax*4 + 0x3c], xmm0
│ ╎ 0x100001c40 4883c008 add rax, 8
│ ╎ 0x100001c44 483df8ff7f00 cmp rax, 0x7ffff8
│ └─< 0x100001c4a 0f82f0fdffff jb 0x100001a40
...
$ r2 -Aqc "e scr.color=0 ; sf sym.multiply5_simd_float__float__float_ ; pdf" mul
...
│ ; CODE XREF from multiply5_simd(float*, float*, float*) @ 0x100001cb0
│ ┌─> 0x100001c70 c5fc280407 vmovaps ymm0, ymmword [rdi + rax]
│ ╎ 0x100001c75 c5fc59c0 vmulps ymm0, ymm0, ymm0
│ ╎ 0x100001c79 c5fc290402 vmovaps ymmword [rdx + rax], ymm0
│ ╎ 0x100001c7e c5fc590407 vmulps ymm0, ymm0, ymmword [rdi + rax]
│ ╎ 0x100001c83 c5fc290402 vmovaps ymmword [rdx + rax], ymm0
│ ╎ 0x100001c88 c5fc590406 vmulps ymm0, ymm0, ymmword [rsi + rax]
│ ╎ 0x100001c8d c5fc290402 vmovaps ymmword [rdx + rax], ymm0
│ ╎ 0x100001c92 c5fc590406 vmulps ymm0, ymm0, ymmword [rsi + rax]
│ ╎ 0x100001c97 c5fc290402 vmovaps ymmword [rdx + rax], ymm0
│ ╎ 0x100001c9c c5fc590406 vmulps ymm0, ymm0, ymmword [rsi + rax]
│ ╎ 0x100001ca1 c5fc290402 vmovaps ymmword [rdx + rax], ymm0
│ ╎ 0x100001ca6 4883c020 add rax, 0x20 ; 32
│ ╎ 0x100001caa 483d00000002 cmp rax, 0x2000000
│ └─< 0x100001cb0 75be jne 0x100001c70
...
The speed-up of the SIMD version to the loop version further increases to 5.68 times:
5 multiplication by loop takes: 0.0219349 sec
5 multiplication by simd takes: 0.00385851 sec
In the results above, it is clear that the higher density of numerical calculation, the more efficient the calculation is.
By organizing the timing data in a table, we will find another interesting fact: the calculation time does not increase significantly with the calculation density when the SIMD (AVX) is used:
Number of multiplications |
Loop (ms) |
SIMD (AVX) (ms) |
SIMD speed-up |
|---|---|---|---|
1 |
5.02769 |
3.39758 |
1.48 x |
3 |
11.1576 |
3.44309 |
3.24 x |
5 |
21.9349 |
3.85851 |
5.68 x |
OpenMP#
OpenMP is a tool that uses multi-threading for parallelism. It is by no means SIMD, but since the source code does not need users to know much about multi-threading, it is introduced here as a comparison to SIMD.
Open requires users to add #pragma omp in the source code to instruct the
compiler to parallelize accordingly:
#pragma omp parallel
{
printf
(
"Hello from thread %d, nthreads %d\n"
, omp_get_thread_num()
, omp_get_num_threads()
);
}
The execution results are:
$ clang++ -Xpreprocessor -fopenmp -std=c++17 -g -O3 -c -o omp.o omp.cpp
$ clang++ -Xpreprocessor -fopenmp -std=c++17 -g -O3 -lomp -o omp omp.o
$ ./omp
Hello from thread 0, nthreads 8
Hello from thread 4, nthreads 8
Hello from thread 3, nthreads 8
Hello from thread 6, nthreads 8
Hello from thread 2, nthreads 8
Hello from thread 7, nthreads 8
Hello from thread 1, nthreads 8
Hello from thread 5, nthreads 8
Users may control the number of threads to be used via an environment variable:
$ env OMP_NUM_THREADS=1 ./omp
Hello from thread 0, nthreads 1
$ env OMP_NUM_THREADS=5 ./omp
Hello from thread 0, nthreads 5
Hello from thread 3, nthreads 5
Hello from thread 1, nthreads 5
Hello from thread 2, nthreads 5
Hello from thread 4, nthreads 5
The full example code can be found in omp.cpp.
Exercises#
Replace the single-precision floating-point vector type
__m256with the double-precision floating-point vector type__m256din the example, and compare the performance with the single-precision version.